Contents
- 0.1 READ ALSO
- 0.2 Ubuntu 22.04 versus 20.04 comparison
- 0.3 Linux’s last command
- 0.4 Agency service
- 0.5 2. Client load balancing
- 0.6 Agent load balancing can be L3/L4(Transmission level) or L7(Application level)。
- 0.7 L3/L4 vs L7
- 0.8 The following is a detailed solution for the client to implement load balancing:
- 1 The above said so much, in the end, which load balancing should be used between services, summarizing the following points:
Take the time to write a simple version of the rpc framework, think about how to engage in load balancing, the easiest way is to put a configuration file to place the service address, read the configuration file directly, and then think of the configuration file can put zk, equivalent to using zk To do configuration center or service discovery. The excellent dubbo project can do this, immediately refer to Google’s grpc, found a great article from Google, read it (also borrowed the picture of Google’s article), very good, want to write some of myself Insights.


Portal: https://grpc.io/blog/loadbalancing/
The rpc communication itself is not complicated. As long as the protocol is fixed, the problem is not big, but the load balancing strategy is worthy of scrutiny.
In general, there are two strategies for load balancing.
Agency service
The client does not know the existence of the server. All its requests go to the proxy service, and the proxy service distributes it to the server, and implements a fair load algorithm. The client may not be trusted, in this case through the user-facing service, similar to our nginx distributing the request to the backend machine.
Disadvantages: The client does not know the existence of the backend, and the client is not trusted, the delay will be higher and the proxy service will affect the throughput of the service itself.
Advantages: Intercepting operations such as monitoring in the middle layer is particularly good.
Figure:
2. Client load balancing
The client knows that there are multiple back-end services, and the client selects the server, and the client can summarize the load information from the back-end server to implement the load balancing algorithm. The simplest implementation of this method is that I directly write a configuration file, when calling, random or polling the server.
Figure:

advantage:
High performance because third-party interaction is eliminated
Disadvantages:
The client can be complicated because the client needs to track the server load and health, and the client implements a load balancing algorithm. Multi-language implementation and maintenance burdens are also cumbersome, and the client needs to be trusted, it is a reliable client.
The above is a description of two load balancing solutions, the following is to say several detailed solutions using proxy mode load balancing
There are many kinds of load balancing in proxy mode.
Agent load balancing can be L3/L4(Transmission level) or L7(Application level)。
In L3/L4 the server and terminate the TCP connection open to the rear end of another connection selected.
L7 Just make an application between the client connection to the server connection to be a middleman.
L3/L4 Level-level load balancing is designed to be minimally processed, with less latency and less expensive than L7-level load balancing because it consumes less resources.
In L7 (application level) load balancing, the load balancing service terminates and resolves the protocol. The load balancing service can examine each request and assign a backend based on the content of the request. This means that monitoring and intercepting operations can be done very conveniently and quickly.
L3/L4 vs L7
The correct way to open is as follows
- The RPC load between these connections varies greatly: L7 is recommended.
- It is important to store or calculate dependencies: it is recommended to use L7 and use cookies or similar routing requests to correct the server.
- Low equipment resources (lack of money): It is recommended to use L3/L4.
- The delay requirements are very strict (that is, fast): L3/L4.
The following is a detailed solution for the client to implement load balancing:
Bulk client
This means that the load balancing policy is implemented in the client, and the client is responsible for tracking the available servers and the algorithms used to select the servers. Clients typically integrate libraries that communicate with other infrastructures such as service discovery, name resolution, quota management, etc., which is complex and large.
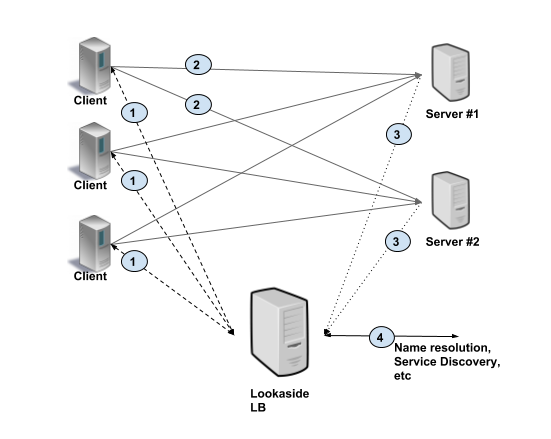
2. Lookaside load balancing (bystander?)
Bystander load balancing, also known as external load balancing, uses backup load balancing, and various functions of load balancing are intelligently implemented in a single, special load balancing service. The client only needs to query this bystander load balancing service. This service will give you the information of the best server, and then you can use this data to request the server. As I said, for example, to register the server information to zk, zk to do load balancing, the client only needs to go to the server data, get the server address, and directly request the server.
Figure:

The above said so much, in the end, which load balancing should be used between services, summarizing the following points:
Very high traffic between the client and the server, and the client is trusted. It is recommended to use a ‘cumbered’ client or Lookaside load balancing.
Traditional setup – Many clients connect to a large number of services behind the proxy, requiring a bridge between the server and the client. Proxy-based load balancing is recommended.
Microservices – N clients, data center has M servers, very high performance requirements (low latency, high traffic), clients can be untrusted, it is recommended to use Lookaside load balancing





Discussion about this post