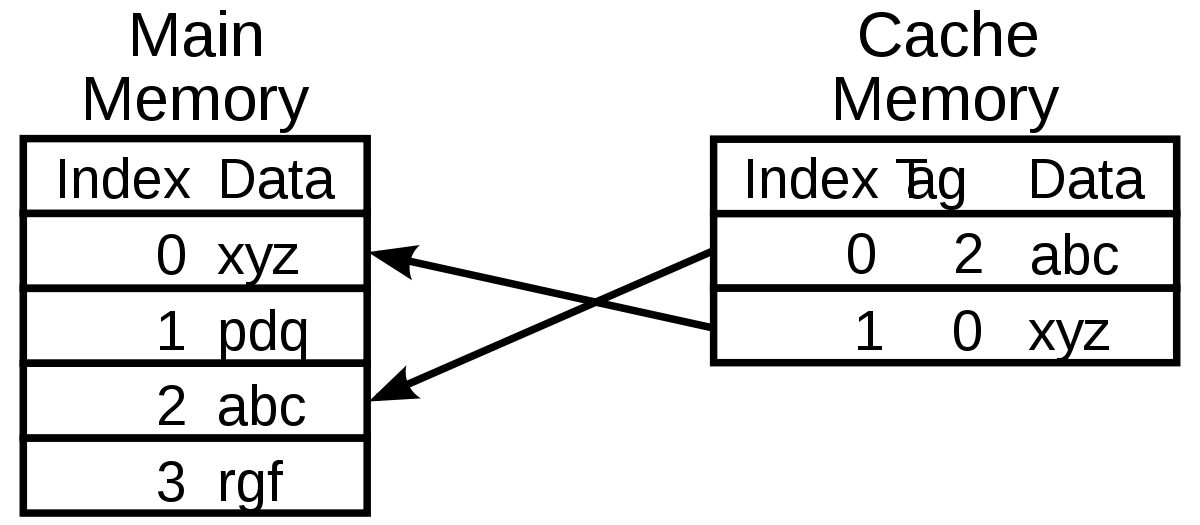
Caching is an important means of increasing the speed of a program. In general, the cache operation is always one or two orders of magnitude faster than the database operation. Therefore, the data that does not change can be cached and cached, which can greatly reduce the query pressure of the database.

This article discusses how to implement caching for database records created on demand.
For example, consider a function that creates an account on demand and returns its ID:
@Transactional
public Long getAccount(Long userId, String currency) {
String key = buildCacheKey(userId, currency);
Long value = getFromCache(key);
if (value == null) {
Account account = getOrCreateAccount(userId, currency);
value = account.id;
putIntoCache(key, value);
}
return value;
}
Account getOrCreateAccount(Long userId, String currency) {
Account account = selectFromDb(userId, currency);
if (account == null) {
account = insertIntoDb(userId, currency);
}
return account;
}
At first glance, it seems that there is no problem. Local testing, everything works fine.
However, in a real environment, the code may be executed concurrently. At this time, there will be a INSERT failure. Only when the database transaction is committed, will the error be reported. At this point, the cache has been added, but the added cache record is invalid, because the later transaction is rolled back, the record will not exist in the database.
What about swollen?
Method one, and then cache the transaction after the transaction is successfully submitted. The question is, when is the transaction submitted? In the case of a nested transaction, it is not necessarily the end of the getAccount() function. It may be the end of the upper call function.
Method two, control concurrency, for example, using a read-write lock. The problem is that in a multi-process environment, read-write locks only work on the current process and cannot limit other processes.
Method three, using distributed read-write locks. Think about it, the cost is bigger than reading the database directly.
Each method is quite complex.
What about swollen?
In fact, the essence of the problem is that it is created without a record, and the creation may fail, but in the case of a record, the result obtained is certainly no problem. If only the existing records are cached, is the problem solved?
Therefore, the solution is to add an identifier to the returned record:
@Transactional
public Long getAccount(Long userId, String currency) {
String key = buildCacheKey(userId, currency);
Long value = getFromCache(key);
if (value == null) {
Account account = getOrCreateAccount(userId, currency);
value = account.id;
if (! account.newlyCreated) {
putIntoCache(key, value);
}
}
return value;
}
Account getOrCreateAccount(Long userId, String currency) {
Account account = selectFromDb(userId, currency);
if (account == null) {
account = insertIntoDb(userId, currency);
account.newlyCreated = true;
}
return account;
}
This caching scheme slightly reduces the performance of the first access, but does not need to consider concurrency issues, so there is no need for read-write locks, so the code is simple and highly reliable.

Discussion about this post